1. 배열(Array)
[배열(Array)이란 무엇인가]
- 거의 모든 언어에서 지원하는 문법이다.
- 배열은 가장 기본적인 자료구조다. 즉, 앞으로 배울 많은 자료구조들이 배열을 부품으로 사용된다.
- 데이터가 적다면 물론 일반 변수를 사용하여 값을 저장하여 사용하면 문제없다.
- 하지만, 데이터가 많아질수록 그룹 관리에 대한 필요성이 생긴다. 이럴 때 배열을 사용하게 된다.
- 즉, 배열은 여러 데이터를 하나의 이름으로 그룹핑해서 관리하기 위한 목적으로 사용하는 자료구조이다.
- element = value + index (value = 저장된 실제 데이터, index는 데이터를 저장 및 조회를 위한 위치 식별자(Index))
- 배열은 반복문과 조합하면 훨씬 더 효율적으로 사용할 수 있다.
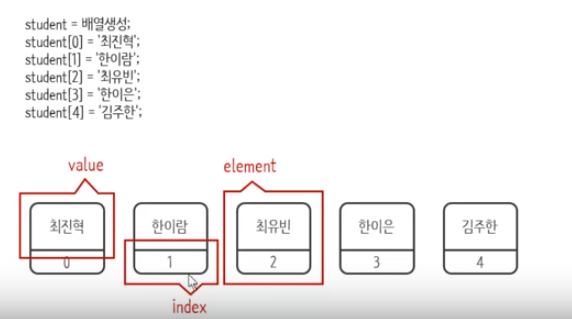
[배열의 생성 방법]
int[] number = new int[5];
number[0] = 10;
number[1] = 20;
위 코드가 바로 배열을 생성하고, 인덱스에 값을 대입하는 코드이다. 또한 더 간단하게 생성을 하고 싶다면
int[] number2 = {10,20,30,40,50};
또는 int[] number3 = new int[]{10,20,30,40,50};
모두 같은 의미이다.
[배열 안에 저장된 값을 가져오는 방법(하나의 데이터를 가져올때)]
이를 위해서 인덱스(Index)가 필요하다.
number[0]; 을 호출하면 0번째 인덱스의 값(value)를 가져오게 된다
[배열 안에 저장된 값을 가져오는 방법(하나의 데이터를 가져올때)]
이를 위해서 반복문이 필요하다. while 또는 for문을 통해 0부터 0!부!터! 배열의 크기만큼(number.length) 반복한다.
[배열 안에 저장된 길이를 구하는 방법]
number.length를 작성하여 number라는 배열에 저장된 데이터 길이를 가져올 수 있다.
작고 가볍다. 또한 단순하다. 그래서 다른 자료구조에서 배열을 부품으로 사용하게 될 것이다.
[배열의 단점 --> 이 단점때문에 ArrayList를 사용한다]
크기가 정해져있기 때문에 데이터 저장이 크기를 초과되면 자동으로 늘어나지 않고 에러를 발생한다.
또한 기능이 없어 단순하다.
2. 리스트(List)
리스트의 특징 : 1. 데이터가 순서대로 저장된다. 2. 중복 데이터를 허용된다.
배열과 리스트의 차이점
(삽입 시)
1. 배열 중간에 데이터를 삽입 시에 덮어쓰기가 되기 때문에 기존의 데이터값은 사라진다!!
2. 리스트 중간에 데이터를 삽입 시 해당 인덱스 이후 데이터들이 한칸씩 뒤로 이동 후 그 위치에 값 저장 (데이터 손실이 없다)
(삭제 시)
1. 배열내에 중간에 데이터를 삭제 시 값(value)은 지워지지만 element는 그대로 남아있다(이 경우 null이 나옴..)
2. 리스트에서 중간에 데이터를 삽입 시 해당 인덱스 삭제 후 데이터들이 한칸씩 앞로 이동하여 빈 공간을 메꿈 (데이터 손실이 없다)
즉, 배열은 빈공간이 생길 수 있지만, 리스트는 빈틈(빈공간)을 허용하지 않는다.
리스트의 기능
- 처음, 끝, 중간에 엘리먼트를 추가/삭제하는 기능
- 리스트에 데이터가 있는지를 체크하는 기능
- C언어의 경우 리스트가 없어서 구현해야 하지만, 최근의 언어는 리스트를 기본적으로 지원한다.
ArrayList number = new ArrayList();
number.add(10);
number.add(20);
number.add(30);
number.add(40);
number.add(50);
자바는 리스트와 배열을 모두 지원하며, 둘을 엄격히 구분하여 직접 적절히 선택하여 사용해야한다.
C언어의 경우는 배열만 있고, 리스트는 직접 구현하거나 남의 구현한 리스트를 사용해야한다.
반면, 파이썬. PHP의 경우는 배열과 리스트를그냥 동일한 것으로 간주하여 사용한다. 즉, 리스트를 몰라도 배열을 쓰면 리스트 기능도 묻혀서 사용된다.
자바는 리스트를 두 가지 지원한다. 똑같은 사용방법을(메소드를) 가지고 있다.
ArrayList의 경우 추가/삭제시 느리지만, 인덱스를 알고 있다면 매우 빠르게 조회할 수 있다.
LinkedList의 경우 추가/삭제 시 빠르지만, 인덱스를 통해 조회하는 속도는 상당히 느리다.
이런 차이를 'Trade-off가 존재한다'
즉, 자기가 구현하고자 하는 것이 무엇이냐에 따라서 배열을쓸지, ArrayList를 쓸지, LinkedList를 쓸지 개발자의 선택에 달렸다....자바는 파이썬. PHP들보다 개발자가 알고 있어야 할것이 더욱더 많지만, 자유도 역시 매우 높다고 할 수 있다. 다시한번 말하지만, 자료구조는 언어마다 다르다.
|
|
추가/ 삭제 |
인덱스 조회 |
|
ArrayList |
느림 |
빠름 |
|
LinkedList |
빠름 |
느림 |
리스트 = 완제품 / 배열 = 부품 --> 대비되는 사이가 아니라, 서로서로 비슷비슷 사용된다고 하 수 있다.
자바에서 ArrayList를 사용하는 방법
자바의 경우 컬렉션 프레임워크이라는 곳 안에 ArrayList 자료구조를 기본적으로 내장하고 있기때문에, C언어와 같이 직접 구현을 하지 않아도 된다. 그렇기 때문에 ArrayList 사용방법을 익힌 후 어떻게 구현되는가를 살펴보도록 한다.
[ArrayList 사용방법 - 생성(Create)]
ArrayList<Integer> number = new ArrayList<>();
[ArrayList 사용방법 - 추가(Insert)]
number.add(10);
number.add(20);
number.add(30);
number.add(10);
//ArrayList안에 데이터를 차례대로 저장
또는
number.add(1,10);
//ArrayList안에 인덱스1 위치에 데이터를 끼워서 저장(그 이후 값들은 뒤로 한 칸씩 밀려)
[ArrayList 사용방법 - 삭제(Remove)]
number.remove(2,10);
[ArrayList 사용방법 - 가져오기(Get)]
number.get(2);
[ArrayList 사용방법 - 크기 가져오기(Size)]
number.size();
[ArrayList 사용방법 - 반복(Iteration)]
Iterator it = number.iterator();
// it변수에 iterator 인터페이스 객체를 리턴함.
hasNext() --> 리턴값이 boolean. 해당 엘리먼트 다음 엘리먼트가 존재하는가를 판별






